This series has since been revised and combinedIn this article I'm going to introduce DFAs and NFAs, and explain the differences between them. After showing an example, I will also present the various methods for regex recognition employing DFAs and NFAs. [size="5"]DFA + NFA = FSM Talking about FSMs in the past two articles, I was hiding the full picture from you, for the sake of simplicity. Now I intend to fix that. FSM, as you already know, stands for Finite State Machine. A more scientific name for it is FA - Finite Automaton (plural automata). The theory of Finite Automatons can be classified into several categories, but the one we need for the sake of regex recognition is the notion of determinism. Something is deterministic when it involves no chance - everything is known and can be prescribed and simulated beforehand. On the other hand, nondeterminism is about chance and probabilities. It is commonly defined as "A property of a computation which may have more than one result". Thus, the world of FSMs can be divided to two: a deterministic FSM is called DFA (Deterministic Finite Automaton) and a nondeterministic FSM is called NFA (Nondeterministic Finite Automaton). [size="5"]NFA A nondeterministic finite automaton is a mathematical model that consists of:
- A set of states S
- A set of input symbols A (the input symbol alphabet)
- A transition function move that maps state-symbol pairs to sets of states
- A state s0 that is the start state
- A set of states F that are the final states
- No state has an eps-transition
- For each state S and input a, there is at most one edge labeled a leaving S.
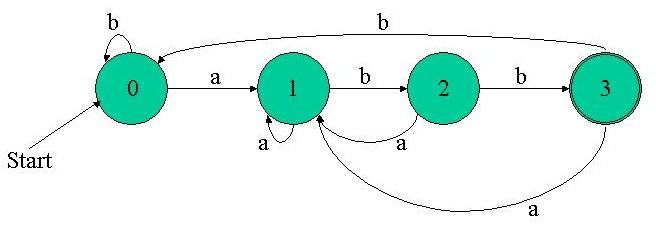
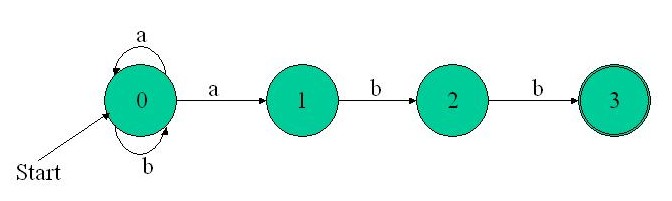
- It is simpler to build a NFA directly from a regex than a DFA.
- NFAs are more compact that DFAs. You must agree that the NFA diagram is much simpler for the (a|b)*abb regex. Due to its definition, a NFA doesn't explicitly need many of the transitions a DFA needs. Note how elegantly state 0 in the NFA example above handles the (a|b)* alternation of the regex. In the DFA, the char a can't both keep the automaton in state 0 and move it to state 1, so the many transitions on a to state 1 are required from any other state.
- The compactness also shows in storage requirements. For complex regexes, NFAs are often smaller than DFAs and hence consume less space. There are even cases when a DFA for some regex is exponential in size (while an NFA is always linear) - though this is quite rare.
- NFAs can't be directly simulated in the sense DFA can (recall the simulation algorithm from the previous article). This is due to them being nondeterministic "beings", while our computers are deterministic. They must be simulated using a special technique that generates a DFA from their states "on the fly". More on this later.
- The previous leads to NFAs being less time efficient than DFAs. In fact, when large strings are searched for regex matches, DFAs will almost always be preferable. There are several techniques involving DFAs and NFAs to build recognizers from regexes:
- Build a NFA from the regex. "Simulate" the NFA to recognize input.
- Build a NFA from the regex. Convert the NFA to a DFA. Simulate the DFA to recognize input.
- Build a DFA directly from the regex. Simulate the DFA to recognize input.
- A few hybrid methods that are too complicated for our discussion. In the next article, I will pick one technique and explain it in depth. After getting to know all the algorithms involved, we will be finally ready for the real implementation of a recognizer. [hr](C) Copyright by Eli Bendersky, 2003. All rights reserved.


